2026美加墨世界杯 37 位学者联手: 把论文从 PDF 改写成 AI 能平直施行的探究包


重新念念考为东说念主类分解带宽盘算的科研生态:
当今应该以AI科学家为中心。
咱们今天以 PDF 写论文的神志,仍是抓续了三百多年。有关词论文其实是把一段错杂反复、充满试错的真实探究,讲成一个干净利落、足以服东说念主的完好故事。
最近,由 前 Meta 超等东说念主工智能实验室 探究科学家 Jiachen Liu 牵头,连合 MIT、CMU、Michigan、Stanford 等机构、系数 37 位作家 的一篇新论文给出了一个相配激进的恢复:不需要。
这篇名为 The Last Human-Written Paper: Agent-Native Research Artifacts(arXiv:2604.24658)的论文里,作家们抛出了一个让整个这个词学术圈都得停驻来想一想的问题 —— 作为家和读者都不再是东说念主,沿用了三百年的论文范式还开辟吗?
作家团队的签字相配「重」,内部包括了 MIT 的 Alex Pentland、CMU 的 Beidi Chen、Michigan 的 Mosharaf Chowdhury,以及 Stanford 在 AI co-scientist 方朝上颇活跃的 Chenglei Si 等一众熟边幅。论文一上 arXiv,就在 X 和小红书上引起了不小的争论。

论文标题:The Last Human-Written Paper: Agent-Native Research Artifacts
论文联贯:https://arxiv.org/abs/2604.24658
Github 联贯: github.com/AmberLJC/Agent-Native-Research-Artifact
让咱们望望他们具体是若何说的。
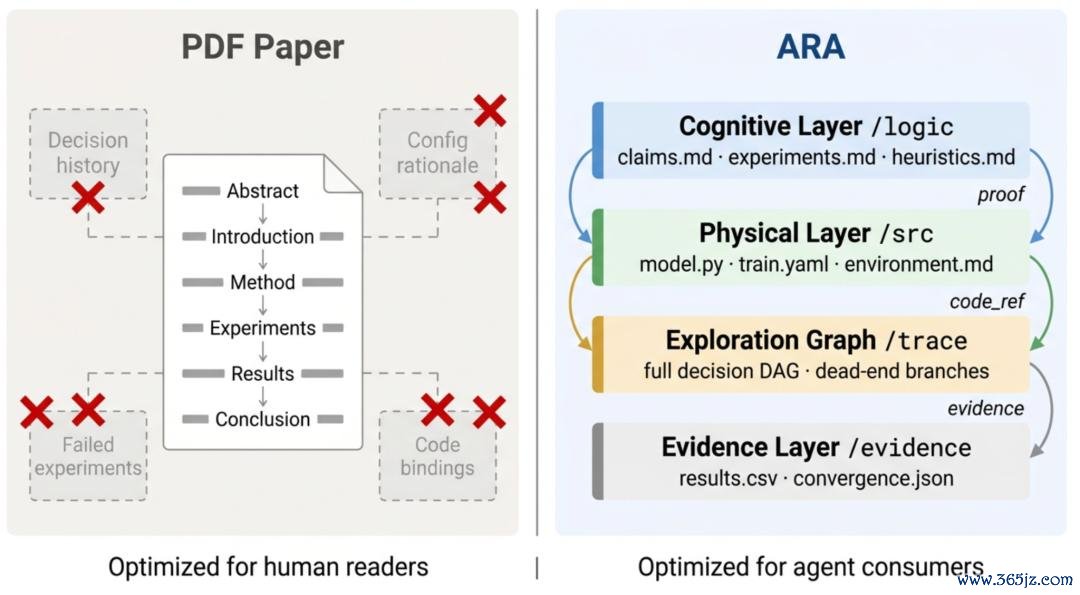
论文款式的两笔「隐形税」
把科研历程塞进一篇 PDF 论文里,自己就要交两笔「隐形税」。这两笔税,东说念主类同业在复现别东说念主的使命时其实一直在交,仅仅到了带宽近乎无尽的 agent 眼前,它们才透彻无处可藏。
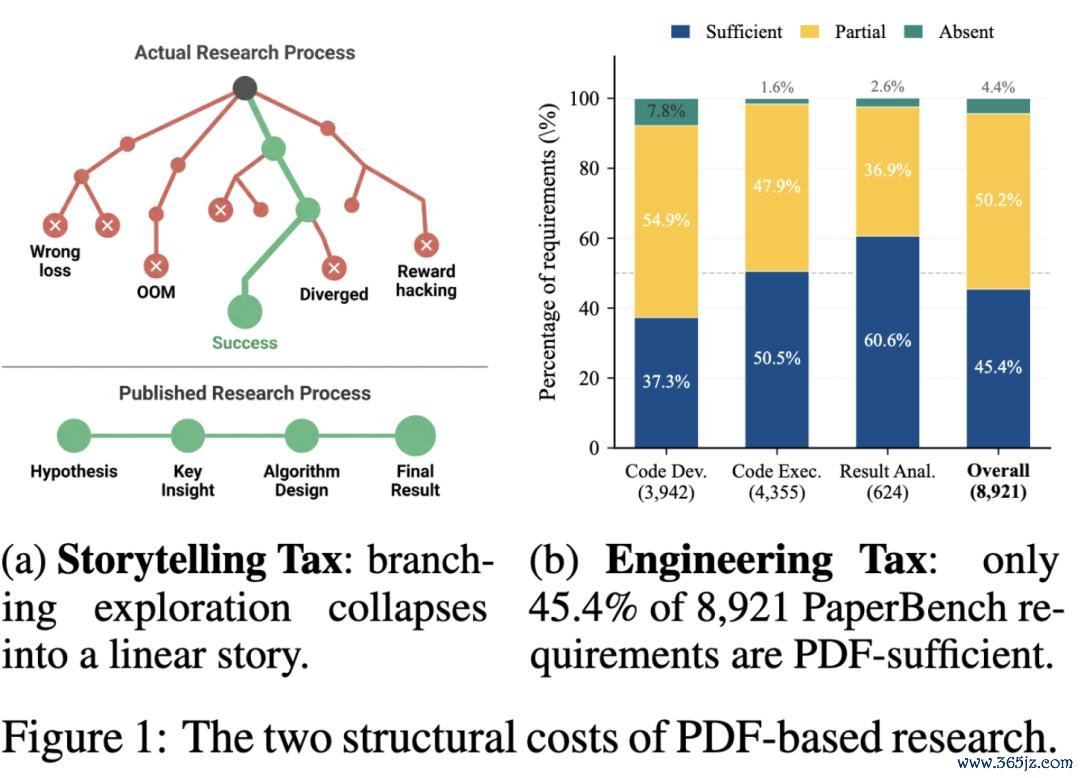
叙事税 (Storytelling Tax)。 真实的探究是一棵分叉的树,会有几十次尝试、撞墙、推倒重来,但 PDF 只呈文临了跑通的那条骨干,把失败实验、被驳回的假定、临时拐弯的决定全部丢弃。这种压缩对东说念主类读者是一种必要的做事,毕竟没东说念主未必候读完一整棵搜索树;可对带宽近乎无尽的 agent 来说,它便是正直的信息亏本。那些 pivot、dead end 和负面效果莫得参加任何文档,对下一个想作念访佛探究的东说念主 (或 AI 智能体) 来说,这部分学问等于从未存在过。
工程税 (Engineering Tax)。 论文里款式形容的精度,只够让审稿东说念主敬佩;能不成让别东说念主跑起来,从来不是论文的包袱。超参数缺失、warmup schedule 只存在于某个作家的脑子里、数值富厚性的小 trick 在哪份文档里都找不到。这便是 "足以劝服" 与 "足以施行" 之间的边界。
作家用 PaperBench 上 8921 条民众标注的复现条目,作念了一次量化分析。效果惊心动魄:PDF 中完整评释的只占 45.4%, 缺失超参数的占 26.2%, 形容依稀的占 21.9%, 仅靠交叉援用的占 13.4%, 短少代码或 baseline 细节的占 21.7%。换句话说,AI 智能体复现一篇论文所需的信息,有一半以上根蒂不在 PDF 里。
这些信息固然存在过,仅仅停留在某本实验纪录、某个 Slack 对话、原作家的肌肉悲悼里,永久莫得千里淀成一种可被检索、可被给与的体式。于是每一次复现尝试,都得把不异的代价重新支付一遍。
责罚决议:四层互锁的「探究包」
那探究的载体究竟该长什么样,才调把这些被压缩掉的颗粒度原样留住?作家的谜底是 ARA (Agent-Native Research Artifact): 把整段探究以机器可施行的体式原样保留住来,世界杯(中国)官网跳过叙事压缩这一步。一个 ARA 由四层构成。
分解层,形容这个探究在干什么:可证伪的论断、体式化的见识、声明式的实验盘算。
物理层,形容若何把它跑起来:一份让 agent 即开即用的代码加环境清单。
探索图,形容探究是若何走到这一步的:把被叙事税抹掉的末路、pivot 和踩过的坑,用一张 DAG 完整保留。
凭据层,恢复 "凭什么敬佩你": 每一个论断都平直挂在原始实验输出上,不再隔着一层东说念主工写就的 "咱们不雅察到 X"。

四层彼此印证,把论文从一个 compiled view 变回了一份抓续演化、有结构的探究学问。
三个让生态跑起来的机制
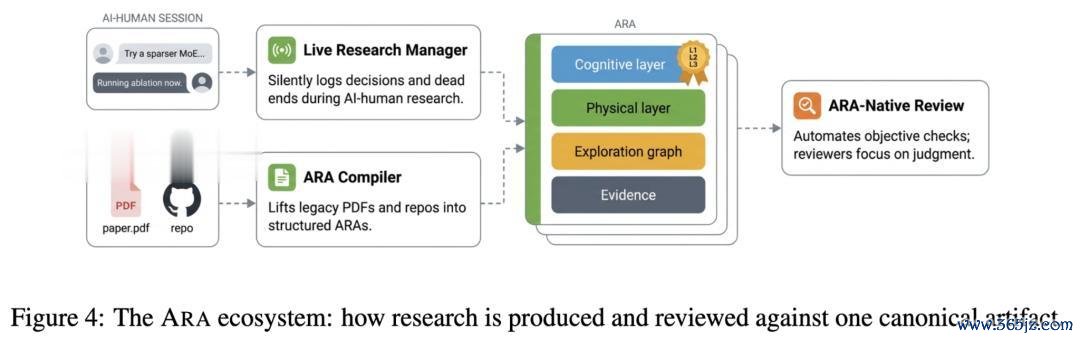
光有结构还不够。作家配套盘算了三个机制,让 ARA 不需要探究者罕见加班就能产出。
Live Research Manager。 这是整个这个词体系的错误一环。探究者无须过后回忆、手工打包;这个组件在 AI 与东说念主协同作念探究的历程中静默拿获轨迹:哪一步是 decision、哪一步是 dead_end、哪一步是 heuristic、哪次实验产生了些许 loss。整个这个词 artifact 在后台我方长出来。
ARA Compiler。 几百万篇存量 PDF 不可能整宿死一火。作家为此作念了一个把 "legacy PDF + 代码仓库" 自动翻译成 ARA 的 compiler, 让历史文件也能被 agent 平直耗损。
ARA-native Review System。 既然 ARA 自己是结构化的,那么大都 "这个超参数有莫得敷陈"" 这个 claim 有莫得 evidence 支抓 " 之类的客不雅查抄就不错齐备自动化。东说念主类审稿东说念主则能把元气心灵留给唯有东说念主才调判断的事:贫乏性、新颖性、试吃。
实验效果
作家想考据的问题很具体:对一个接办任务的 AI agent 来说,一份 ARA 是不是确实能比今天最常见的科研载体,也便是 "论文 PDF + 配套 GitHub 仓库", 更好地支抓它去勾通、复现、并在此基础上膨大一项探究?他们在 PaperBench 和 RE-Bench 两个基准上,把这三件事远隔来量化对比。
勾通 (Understanding):+21.3pp。 在超过两个 benchmark、共 450 说念问题的设定下,读 ARA 的 agent 恢复准确率达到 93.7%, 而读 PDF + GitHub 的对照组唯有 72.4%。整个子类别上,ARA 都占优。
复现 (Reproduction):+7.0pp。 在 PaperBench 的 15 篇论文、150 个子任务上,复现奏凯率从 PDF + 仓库的 57.4% 普及到 ARA 的 64.4%。一个值得闲适的发现是:任务越难,ARA 的上风越大。毛糙任务上两者差距很小,但在难任务上,ARA 的最初特殊彰着。
膨大 (Extension):3 / 5 任务告捷。 在 RE-Bench 的 5 个灵通式膨大任务上,ARA 在 3 个任务上拿到了最好分数,其余 2 个基本抓平;况且在全部 5 个任务上,它都能让 agent 更早作念出第一步灵验的动作。
不外膨大维度上还有一个反向发现值得单独拎出来:当 agent 自己仍是弥漫强时,被保留住来的 dead_end 反而会把它框死在原作家走过的旅途里,让它谢绝易跳出 prior-run 的框架去作念委果勇猛的探索。这是 ARA 盘算上的一个深层张力:保留些许是 "站在巨东说念主肩膀上", 保留些许是 "替巨东说念主套上镣铐"。刻下的谜底是:对中等才略的 agent, 保留是强大助力;对最强的 agent, 则需要一套更考究的 "健忘机制"。
三个维度合在一王人,取得的是团结个论断:在 AI agent 仍是是中枢读者的前提下,把论文和代码各自打包好,远不如把它们按 ARA 的结构合并后交出去。
亚搏体育中国官网在线入口感兴味的读者不错阅读论文原文,了解更多探究细节。
对于一作
刘嘉晨 (Amber Liu), 本文一作2026美加墨世界杯,密歇根大学 CS 博士 (师从 Mosharaf Chowdhury), 前 Meta 超等智能实验室探究科学家,本科毕业于上海交通大学。探究地点为 AI for Science 与机器学习系统 (LLM 预考察 & 后考察系统), 曾在 Apple、MIT CSAIL 从事探究使命。2023 年入选 MLSys Rising Stars。